深層学習において、一般的な画像認識のための分類器としてVGG[1]やGoogLeNet[2]、ResNet[3]など、認識精度の高いネットワーク構造がここ数年で発明されてきました。PyTorchやTensorFlowなどの深層学習ライブラリでは、これらを既存のネットワークとして簡単に再利用することができます。
ところで、画像認識を2次元CADへ応用させる技術は今のところあまりなされていないため、試しに実験を行ってみました。CAD図面は通常、直線、曲線や文字など、写真に比べるとノイズが少ないのが特徴と言えます(図1)。ここで言うノイズとは、ピクセル単位のノイズや、また、図形の意味的なノイズでもあります。例えば高木は円と記号で表されるように、抽象化された図形によって表現されます。ピクセルデータの側面では、情報的にかなりスパースと言うことができるかもしれません。
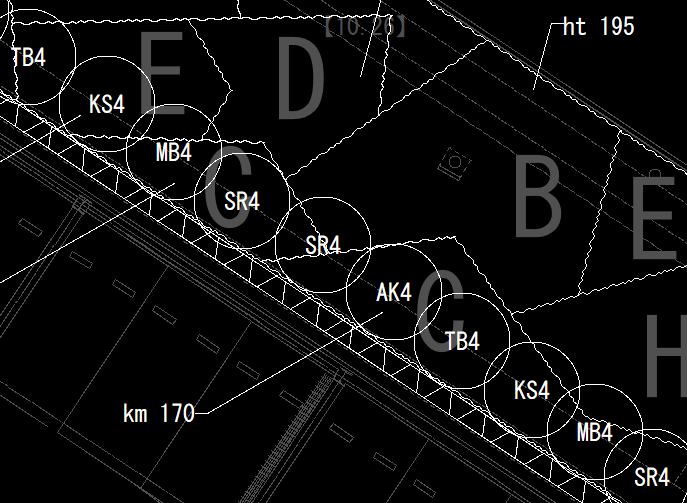 図1. 一般的な造園土木のCAD図面
図1. 一般的な造園土木のCAD図面
まず考えられるアプローチとして、既存のCNN構造をそのまま使うことは可能かどうかということです。また、その場合、教師データのサンプル数、各種チューニングパラメータと分類精度の関係はどうなっているのでしょうか。
教師データ
ここで、教師データは縦横224pxの画像ファイルを2000枚ほど手作業で準備しました。それぞれ約650枚ずつの高木画像、生垣画像、低木画像とし、サンプルの90%を訓練データ、残りをテストデータとして使用します。以下にそれぞれの例を示します。
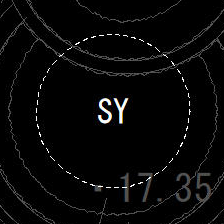
図2. 高木の記号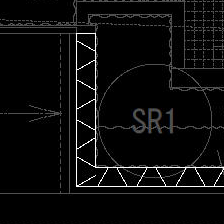
図3. 生垣の記号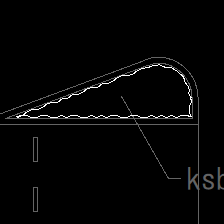
図4. 低木の記号
これらはCADソフトウェアのスクリーンショットから切り出し、PNG画像として保存しました。
VGG vs. ResNet
PyTorhで簡単に試せるネットワークがいくつかあり、ここではVGG16とResNet18を利用し、比較を行いました。VGGは比較的シンプルな構造ですが、全結合層が大きく、メモリを多く必要とするというデメリットがあります。後発のResNetはその点において改善がなされており、しかしながら、構造が複雑です。以下、2つの比較です。

学習時間は、ResNetが10分、VGGが3時間でした。なお、パフォーマンス、学習時間、学習の安定性の3つの観点で、ResNetが優れていました。これは学習時のバックプロパゲーションにおいて、勾配消失や勾配爆発を防ぎ、勾配を深い層まで伝搬させるネットワーク構造が重要であると言えます。
AWS GPUインスタンス
モダンなCNNの学習にローカルPCを使用すると、遅いのに加え、他の仕事ができなくなるので、その2つの理由によりあまり良い選択ではありません。そこで、GPUを使えるクラウドを利用することでこの問題を解決しています。この実験では、Amazon Web Services(AWS)のP2インスタンスをスポットリクエストで利用することで、優れた計算資源を安く利用させていただいています。
まとめと課題
この実験では、CNNを利用したCAD画像の分類問題において、各クラス1000サンプルほどの比較的少ない教師データで98%の精度を出すことができました。実際のタスクにどう応用できるかは、今後の課題となります。
参考文献
[1] Very Deep Convolutional Networks for Large-Scale Image Recognition
https://arxiv.org/pdf/1409.1556
[2] Going Deeper with Convolutions
https://www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf
[3] Deep Residual Learning for Image Recognition
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf