The project PlasticAI was exhibited at Maker Faire Taipei 2019.
The faire itself was full of people and tech-enthusiasts. And exhibitors were so creative that I’ve given additional inspiration from them. Especially it was so encouraging that there were a few people who were very interested in the project PlasticAI in terms of technologies and the marine environment. I greatly appreciate it.
The main takeaway from the show was “the AI does work”. The precision of detecting plastic bottle-caps was so good in spite of the fact that no training on any negative samples was done. But it also turned out that the AI is not enough if I want to pick something up in the real world because the object detection system tells no other information but the bounding box in the input image, which means there is no way to determine the actual distance between the actuator and the target object. Some extra sensors should definitely be added to do this job better.
To demonstrate PlasticAI in the exhibition, I have built a delta robot on which the AI to be put. The robot has 3 parallel link arms and is actuated with 3 servo motors. The main computer for the detection that I used is NVIDIA Jetson nano, which can perform full YOLO with approx 3.5 FPS. I will go into the details about the robot itself in the later article.
The strength of 3d-printed parts is acceptable for this demonstration. But I should try metal parts, too.
I’m now working on the project “PlasticAI” which is aiming for detecting plastic wastes on the beach. As an experiment for that, I have trained object detection system with the custom dataset that I collected in Expedition 1 in June. The result of this experiment greatly demonstrates the power of the object detection system. Seeing is believing, I’ll show the outcomes first.
the resulted images with predicted bounding boxes
The trained model precisely predicted the bounding box of a plastic bottle cap.
Training Dataset
Up until I conducted a model training, I haven’t been sure about whether the amount of training dataset is sufficient. Because plastic wastes are very diverse in shapes and colors. But, as a result, as far as the shape of objects are similar, this amount of dataset has been proved to be enough.
In the last expedition to Makuhari Beach in June, I’ve shot a lot of images. I had no difficulty finding bottle caps on the beach. That’s sad, but I winded up with 484 picture files of bottle caps which can be a generous amount of training data for 1 class.
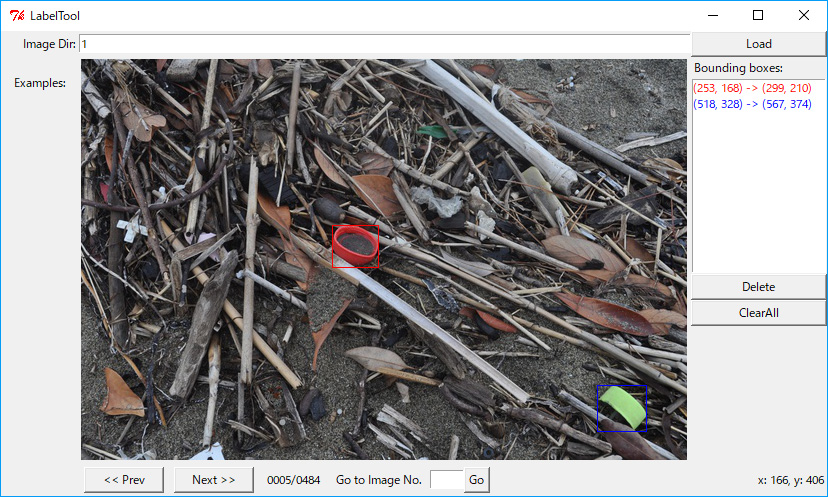
The demanding part of preparing training data is annotating bounding boxes on each image files. I used customised BBox-Label-Tool [1].
a sample of bounding-box annotation
Just for convenience, I open-sourced the dataset on GitHub[2] so that other engineers can use it freely.
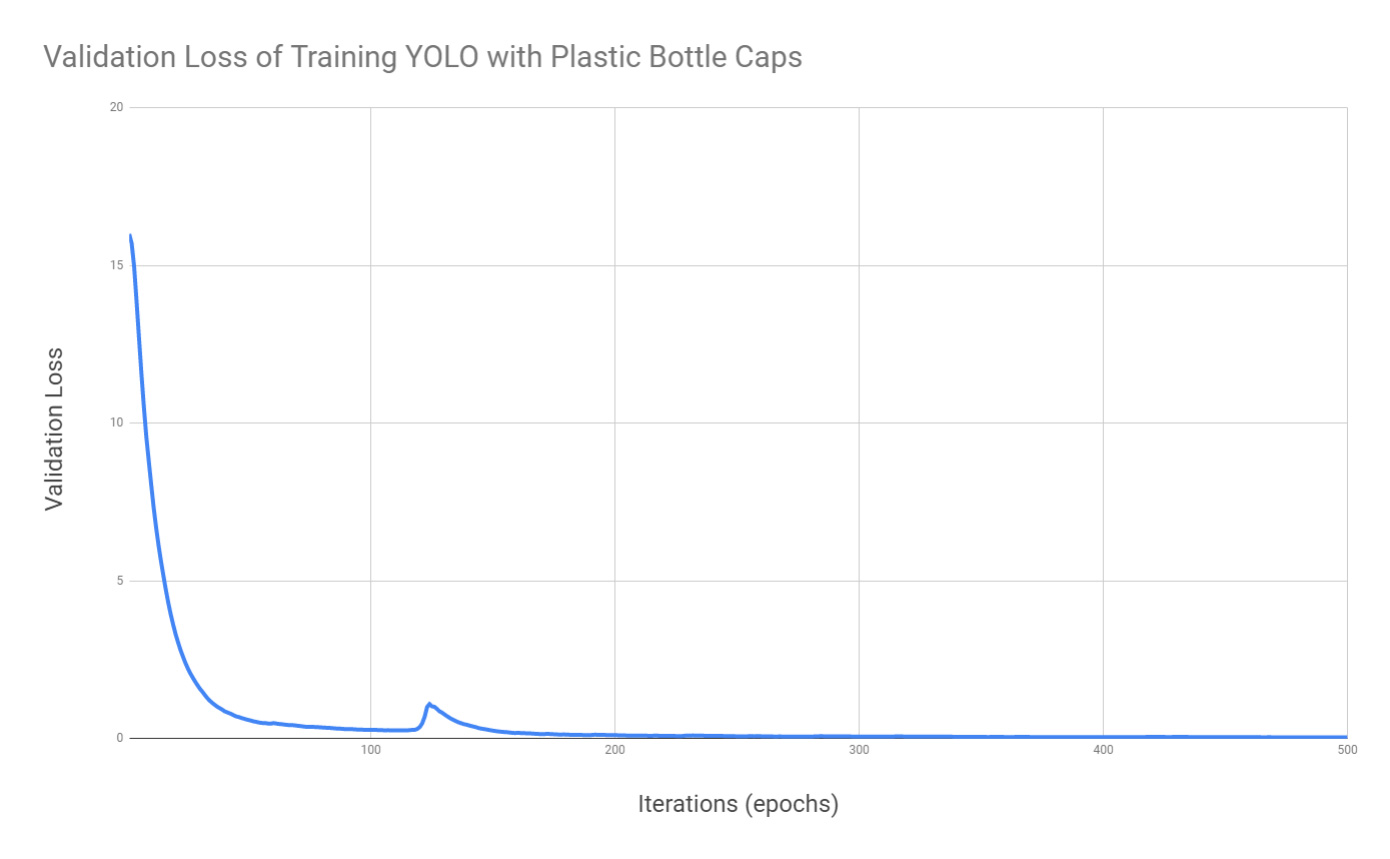
Training was done on AWS’s P2 instance, taking about 20 minutes. Over the course of the training process, the validation loss drops rapidly.
One thing that I want to note is that there is a spike in the middle of training, which probably means that the network escaped from local minima and continued learning.
The average validation loss eventually dropped to about 0.04, although this score doesn’t simply tell me that the model is good enough to perform intended detection.
Test
In the test run, I used a couple of images that I have put aside from the training dataset. It means that these images are unknown for the trained neural network. The prediction was done so quickly and I’ve got the resulted images.
the resulted images with predicted bounding boxes
It’s impressive that the predicted bounding-boxes are so precise.
Recap
The main takeaway of this experiment is that detecting plastic bottle caps just works. And it encourages further experiments.
Deep-learning-based object detection is a state-of-the-art yet powerful algorithm. And over the course of the last couple of years, a lot of progress has been made in this field. It has momentum and huge potential for the future, I think.
Now is the high time for actual implementation to solve problems. The project “Microplastic AI” is aiming for building the AI that can detect plastic debris on the beach. And object detection is going to be a core technology of the project.
As in the last article, training YOLO with 1 class was a good success (Train Object Detection System with 1 Class). But in order to delve into this system even deeper, I extended the training dataset and ended up to have 3 classes. Just for your convenience, I open sourced the training data as follows.
The training data has 524 images in total. In addition to that, the dataset has text files in which bounding boxes are annotated. And some config files also come with. At first, I had no idea if this amount of data has enough feature information to detect objects, but the end result was pleasant.
Here’s one of the results.
An interesting takeaway is the comparison between the model trained with 1 class and the one with 3 classes. Prediction accuracy of the model with 3 classes obviously outperforms. I think this is because a 1 yen coin and a 100 yen coin have similar color, and having been both classes trained, the neural network seems to have learned a subtle difference between those classes. This means that if you’re likely to have similar objects
Let’s say you have an image that has an object that you’re going to detect, and visually similar objects may be in the adjacent space. In a situation like that, you should train not only your target object but also similar objects. Because that would allow you a better detection accuracy.
With this experiment done successfully, the microplastic AI project has been one step closer to reality.
It’s imaginable that learning plastic fragments is challenging for the AI in many ways because plastic wastes, in general, are very diverse in shapes or colors, that makes harder to obtain the ability to generalize what plastic waste should look like. So it’ll be a good approach to split up the problem into several stages. For a starter, I’ll be focusing on detecting plastic bottle caps.
Both luckily and sadly, the beach that day was full of plastic bottle caps. And I took pictures of them with the digital camera and my smartphone, which winded up with about 500 images in total, which can be a generous amount of training data for 1 class of object.
It’s still hard for me though to tell if this works until I train the neural network. Let’s give it a shot.
the predicted bounding box by YOLOv2 after training 1000 epochs
YOLO and Darknet
YOLO is a state-of-the-art object detection system, which I believe it has a significant potential for applying AI to many problem-solving. Darknet is an open source neural net framework written in C language, on which YOLO is built.
The official repository of YOLO can be found here[1], which you should read through its README for better understanding of how to use it. And the paper can be found here[2] just in case you want to delve into the concept of YOLO in depth.
This article is aiming for showing you the actual steps and commands for training YOLO. Putting the ground algorithm aside, do run YOLO by your own hands because it’s a lot easier for you to understand how it works. I believe it’ll help you with implementing your own object detection system.
Get your EC2 booted
In this tutorial, everything is going to be done on AWS using AWS’s Deep Learning AMI, which allows you to kickstart. Therefore whether your local machine is Windows or Mac doesn’t matter at all.
just hit a button like this
I strongly recommend that you should train your YOLO on Linux OS(whatever Ubuntu or Amazon Linux you choose) because compiling Darknet on Linux is way easier. I tell you this because I actually tried it both on Linux and Windows.
By the way, DLAMI(s) has been constantly updated, and the latest version will work fine.
Training YOLO definitely needs the GPU computation capability. Well, with CPU(s), it would never be going to get it done before you give it up. I chose an EC2’s P2 instance booted with DLAMI(Amazon Linux version). (P3 instances will work even better.)
Login to your EC2 console from your local machine(it can differ a bit according to your vm’s region).
$ cd darknet
$ ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23
The output will be something like below.
yolo-obj
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32
2 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs
3 max 2 x 2 / 2 208 x 208 x 64 -> 104 x 104 x 64
4 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
5 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
6 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
7 max 2 x 2 / 2 104 x 104 x 128 -> 52 x 52 x 128
8 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
9 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
10 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
11 max 2 x 2 / 2 52 x 52 x 256 -> 26 x 26 x 256
12 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
13 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
14 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
15 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
16 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
17 max 2 x 2 / 2 26 x 26 x 512 -> 13 x 13 x 512
18 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
19 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
20 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
21 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
22 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
23 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs
24 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs
25 route 16
26 conv 64 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 64 0.044 BFLOPs
27 reorg / 2 26 x 26 x 64 -> 13 x 13 x 256
28 route 27 24
29 conv 1024 3 x 3 / 1 13 x 13 x1280 -> 13 x 13 x1024 3.987 BFLOPs
30 conv 30 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 30 0.010 BFLOPs
31 detection
mask_scale: Using default ‘1.000000’
Loading weights from darknet19_448.conv.23…Done!
Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005
Resizing
544
Loaded: 0.000044 seconds
Region Avg IOU: 0.201640, Class: 1.000000, Obj: 0.187609, No Obj: 0.530925, Avg Recall: 0.090909, count: 11
Region Avg IOU: 0.117323, Class: 1.000000, Obj: 0.381525, No Obj: 0.531642, Avg Recall: 0.000000, count: 10
Region Avg IOU: 0.156779, Class: 1.000000, Obj: 0.301009, No Obj: 0.530801, Avg Recall: 0.000000, count: 12
Region Avg IOU: 0.083861, Class: 1.000000, Obj: 0.239799, No Obj: 0.530281, Avg Recall: 0.000000, count: 10
Region Avg IOU: 0.126977, Class: 1.000000, Obj: 0.426366, No Obj: 0.531593, Avg Recall: 0.000000, count: 8
Region Avg IOU: 0.156623, Class: 1.000000, Obj: 0.337786, No Obj: 0.529291, Avg Recall: 0.000000, count: 13
Region Avg IOU: 0.134743, Class: 1.000000, Obj: 0.368207, No Obj: 0.529858, Avg Recall: 0.000000, count: 9
Region Avg IOU: 0.105239, Class: 1.000000, Obj: 0.337773, No Obj: 0.529503, Avg Recall: 0.000000, count: 11
1: 510.735443, 510.735443 avg, 0.000000 rate, 7.901008 seconds, 64 images
Sit tight until several hundreds of iteration are completed, and then hit Ctrl + c to halt training. With that be done, you can test your trained YOLO.
$ ./darknet detector test cfg/obj.data cfg/yolo-obj.cfg backup/yolo-obj_last.weights test_image.jpg
If everything is done as expected, you’ll get predictions.jpg with detected bounding box(es). Voila!
predictions.jpg
Recap
Did you get your network trained as expected? Because this technology has been frequently revised, you might have some mismatch due to the framework’s version or CUDA version. So please do update surrounding information yourself and let me know if there is any of those. And YOLO is designed to detect up to 9000 classes, so you’re greatly encouraged to try out training it for multiple classes. Application of this technology is endless, I believe.