YOLO and Darknet
YOLO is a state-of-the-art object detection system, which I believe it has a significant potential for applying AI to many problem-solving. Darknet is an open source neural net framework written in C language, on which YOLO is built.
The official repository of YOLO can be found here[1], which you should read through its README for better understanding of how to use it. And the paper can be found here[2] just in case you want to delve into the concept of YOLO in depth.
This article is aiming for showing you the actual steps and commands for training YOLO. Putting the ground algorithm aside, do run YOLO by your own hands because it’s a lot easier for you to understand how it works. I believe it’ll help you with implementing your own object detection system.
Get your EC2 booted
In this tutorial, everything is going to be done on AWS using AWS’s Deep Learning AMI, which allows you to kickstart. Therefore whether your local machine is Windows or Mac doesn’t matter at all.
I strongly recommend that you should train your YOLO on Linux OS(whatever Ubuntu or Amazon Linux you choose) because compiling Darknet on Linux is way easier. I tell you this because I actually tried it both on Linux and Windows.
By the way, DLAMI(s) has been constantly updated, and the latest version will work fine.

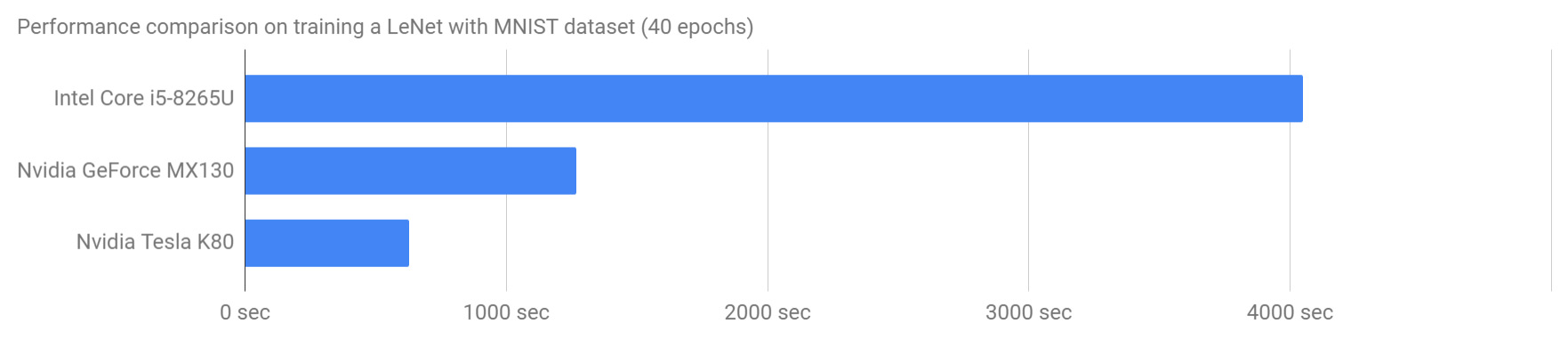
Training YOLO definitely needs the GPU computation capability. Well, with CPU(s), it would never be going to get it done before you give it up. I chose an EC2’s P2 instance booted with DLAMI(Amazon Linux version). (P3 instances will work even better.)

Login to your EC2 console from your local machine(it can differ a bit according to your vm’s region).
$ ssh -i “<your ssh key>.pem” root@ec2-<your vm’s ip>.ap-northeast-1.compute.amazonaws.com
Switch the CUDA version to 10.
$ sudo rm /usr/local/cuda
$ sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
Copy the codebase of YOLO from the AlexeyAB’s repository.
$ cd
$ git clone https://github.com/AlexeyAB/darknet.git
$ cd darknet
$ vim Makefile
Here’s some configuration for using GPU,
on the line 1 and 2, make them like so.
GPU=1
CUDNN=1
Compile Darknet.
$ make
Download an initial weights file.
$ wget https://pjreddie.com/media/files/darknet19_448.conv.23
Clone training dataset and config files.
$ cd
$ git clone https://github.com/sudamasahiko/dataset100jpy
$ cp -r dataset100jpy/* darknet
Start training.
$ cd darknet
$ ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23
The output will be something like below.
yolo-obj
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32
2 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs
3 max 2 x 2 / 2 208 x 208 x 64 -> 104 x 104 x 64
4 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
5 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
6 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
7 max 2 x 2 / 2 104 x 104 x 128 -> 52 x 52 x 128
8 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
9 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
10 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
11 max 2 x 2 / 2 52 x 52 x 256 -> 26 x 26 x 256
12 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
13 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
14 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
15 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
16 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
17 max 2 x 2 / 2 26 x 26 x 512 -> 13 x 13 x 512
18 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
19 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
20 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
21 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
22 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
23 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs
24 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs
25 route 16
26 conv 64 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 64 0.044 BFLOPs
27 reorg / 2 26 x 26 x 64 -> 13 x 13 x 256
28 route 27 24
29 conv 1024 3 x 3 / 1 13 x 13 x1280 -> 13 x 13 x1024 3.987 BFLOPs
30 conv 30 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 30 0.010 BFLOPs
31 detection
mask_scale: Using default ‘1.000000’
Loading weights from darknet19_448.conv.23…Done!
Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005
Resizing
544
Loaded: 0.000044 seconds
Region Avg IOU: 0.201640, Class: 1.000000, Obj: 0.187609, No Obj: 0.530925, Avg Recall: 0.090909, count: 11
Region Avg IOU: 0.117323, Class: 1.000000, Obj: 0.381525, No Obj: 0.531642, Avg Recall: 0.000000, count: 10
Region Avg IOU: 0.156779, Class: 1.000000, Obj: 0.301009, No Obj: 0.530801, Avg Recall: 0.000000, count: 12
Region Avg IOU: 0.083861, Class: 1.000000, Obj: 0.239799, No Obj: 0.530281, Avg Recall: 0.000000, count: 10
Region Avg IOU: 0.126977, Class: 1.000000, Obj: 0.426366, No Obj: 0.531593, Avg Recall: 0.000000, count: 8
Region Avg IOU: 0.156623, Class: 1.000000, Obj: 0.337786, No Obj: 0.529291, Avg Recall: 0.000000, count: 13
Region Avg IOU: 0.134743, Class: 1.000000, Obj: 0.368207, No Obj: 0.529858, Avg Recall: 0.000000, count: 9
Region Avg IOU: 0.105239, Class: 1.000000, Obj: 0.337773, No Obj: 0.529503, Avg Recall: 0.000000, count: 11
1: 510.735443, 510.735443 avg, 0.000000 rate, 7.901008 seconds, 64 images
Sit tight until several hundreds of iteration are completed, and then hit Ctrl + c to halt training. With that be done, you can test your trained YOLO.
$ ./darknet detector test cfg/obj.data cfg/yolo-obj.cfg backup/yolo-obj_last.weights test_image.jpg
If everything is done as expected, you’ll get predictions.jpg with detected bounding box(es). Voila!
Recap
Did you get your network trained as expected? Because this technology has been frequently revised, you might have some mismatch due to the framework’s version or CUDA version. So please do update surrounding information yourself and let me know if there is any of those. And YOLO is designed to detect up to 9000 classes, so you’re greatly encouraged to try out training it for multiple classes. Application of this technology is endless, I believe.
Reference
[1] YOLO: Real-Time Object Detection
https://pjreddie.com/darknet/yolo/
[2] You Only Look Once: Unified, Real-Time Object Detection
https://pjreddie.com/media/files/papers/YOLOv3.pdf