この記事で得られるもの
- 理論はさておき画像AIの実装方法が分かる
- 教師データを何枚準備すればよいかを考えるきっかけ
- 具体的なコード、ライブラリ、環境などの情報
はじめに
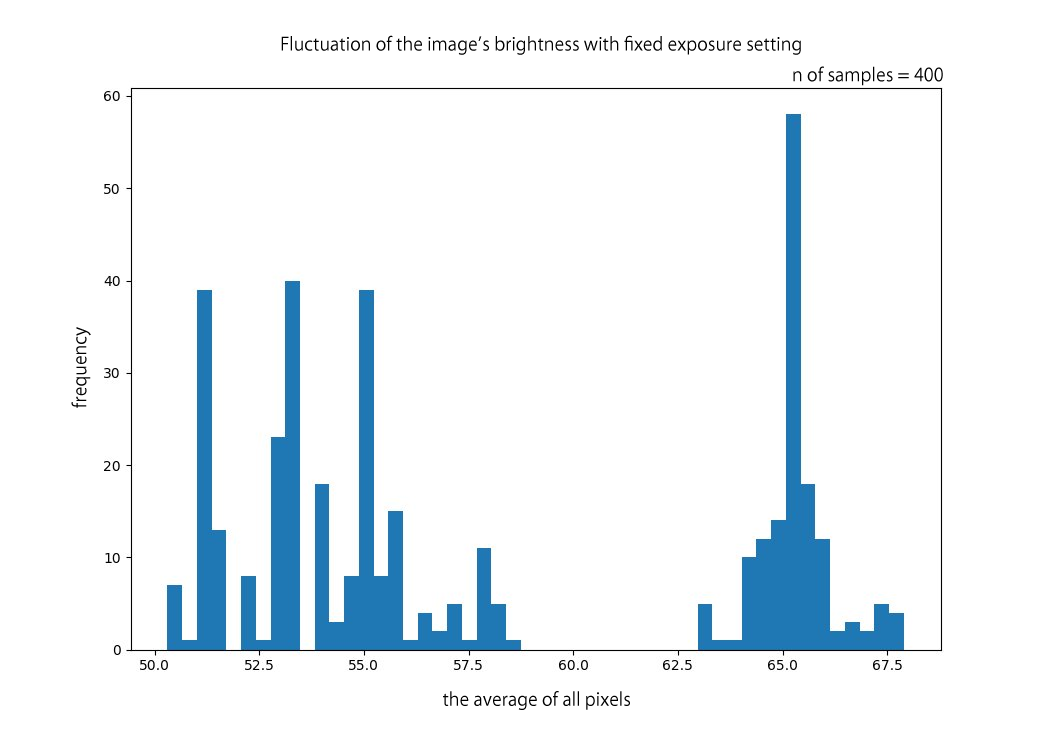
まさに今、皆さんがAIを実装する時代が来ています。ResNetやGoogLeNet、VGGなど、近年の優れたディープニューラルネットワークの発明、そして、クラウドでのGPU環境の勃興も手伝って、今までになく深層学習の応用実装に手が届く時代となりました。しかし、いざ画像分類のモデルを実際に作成するとなると、教師データをどれくらい準備すればよいか試行錯誤するでしょう。もっとも、データの質により、必要な教師データの数は変わってきます。そして、あなたの分類問題自体の本質的な難易度も必要な教師データ数に影響を与えるでしょう。しかし、データの質を定量的に評価するのは難しく、定性的判断と経験値が必要です。
深層学習の理論や数学はさておき、実際に実装作業を行うことで、AI学習を肌感覚で体験してみてはいかがでしょうか。ここでは具体的な分類モデルの作成を行い、2回にわたる試行–教師データの質が原因で失敗した例(試行1)と、その後、それを踏まえて教師データを作り直し、うまくいった例(試行2)とをそれぞれご紹介していきます。
お題 〜カルダモンを分類しよう〜

畳み込みニューラルネットワーク(以下、CNN)の応用として、ここではシンプルな画像の分類問題に取り組みます。CNNでの画像分類は、セキュリティの問題[1]を除けば、技術的には確立されたと言ってもよいでしょう。
はじめに、小さい物体は教師データの撮影が作業的に簡単だと考え、(やや唐突なのはご了承いただいて)スパイスの一種であるカルダモン(以下、試料A)とその近縁種であるブラックカルダモン(ビッグカルダモンとも。以下、試料B)の分類を課題とします。ここで、分類の難易度という観点では「難しすぎず簡単すぎず」を考慮しました。なぜなら、例えば五円玉と十円玉のような簡単な分類はニューラルネットワークを使わずとも単純な画像処理で実現可能だからです。その点、カルダモンの分類はクラス間で形が似ており、色が微妙に異なるという点で、AIに適した分類問題と考えました。
教師データを撮影する
深層学習による画像分類は、一般的に大量の教師データが必要です。多くの画像データを準備するにあたり、インターネットから入手するか、あるいは自分で撮影を行いましょう。今回は撮影します。スマートフォンでカメラ撮影する方法は、まず第一選択となるかと思いますが、撮影角度などの条件を細かく調整したいので、専用の撮影装置を製作しました。仕組みはWEBカメラとモーター制御の円卓をRaspberry Piでコントロールしています。これにより半自動で物撮りをしていきます。

部品はCADで設計し、3Dプリンターで製作しました。
AIの道具たち
ここでAIの道具として、深層学習ライブラリと学習手法を簡単にご紹介します。
PyTorch、ResNet
PyTorch[2]は、高レベルで柔軟な深層学習ライブラリです。また、各種の学習済みネットワークがすぐに利用でき便利です。ここでは高速な学習と高い認識を誇るResNet[3]を使い、あらかじめ学習された重みをもとに学習しなおす転移学習[4]という方法をとります。
転移学習(Transfer Learning)とは
CNNの画像認識をやるとき、ネットワークの重みを初期値から学習させることはまれで、一般的には学習済みの重みが再利用されます。これは転移学習と呼ばれ、比較的少ない教師データ、かつ短時間でネットワークを学習させられるというメリットがあります。これに関しては以下のチュートリアルが分かりやすいです。
TRANSFER LEARNING TUTORIAL
教師データをディレクトリに振り分ける
教師データのディレクトリ構造は以下のように学習用と評価用(それぞれ「train」、「val」に分け、下層にクラスごとにディレクトリを作ります。学習の際はルートのディレクトリ名(ここではcardamon1)を指定します。
cardamon1
├train/
│ ├black/ (400ファイル)
│ └green/ (400ファイル)
└val/
├black/ (100ファイル)
└green/ (100ファイル)
ここでは、ファイルの振り分け用に以下のようなスクリプトを作成しました。
(split_image_data.py)
試行1: とにかく数を、しかし過学習に
試料AとBをそれぞれ5サンプル、2台のWEBカメラで7.2度刻みで回転させながら撮影という戦略を取ります。これにより、サンプルごとに100枚を撮影でき、合計で1000枚の画像データが得られます。この時点では、十分な量の教師データだろうと考えていました。
試行1: 学習させる
学習を行う環境は、クラウドのGPUインスタンスが安価で便利です。ここではAWS(Amazon Web Services)のP2インスタンスをDeep Learning AMIで起動し、ライブラリやツールの準備をほとんどすることなくすぐに学習にとりかかります。AWSでの基本的なPyTorchの学習は以下をご参考にしてください。
PyTorchでシンプルな畳み込みニューラルネットワークを作ろう
AWSインスタンスを作成できたら、SSHで接続し教師データと学習用スクリプトをアップロードしましょう。WinSCPなどのファイル転送クライアントを利用してもよいでしょう。学習用スクリプトの全コードは以下です。
(transfer_learning.py)
学習が完了するとモデルが保存されるので、ダウンロードします。
試行1: 結果
結果的には過学習を起こしました。クラスにつき5サンプルという試料の少なさは、たとい細かく撮影角度を変えて大量の画像を用意したところで、各クラスの特性を一般化するには情報が少なすぎると推察できます。学習用スクリプトを実行した結果が以下です。
# python transfer_learning.py cardamon1
Epoch 0/9
----------
train Loss: 0.5644 Acc: 0.7242
val Loss: 0.3478 Acc: 0.9075
...
...
...
Epoch 9/9
----------
train Loss: 0.2609 Acc: 0.8952
val Loss: 0.0930 Acc: 0.9884
Training complete in 1m 33s
Best val Acc: 0.994220
試行2:
試行1ではサンプル数が小さく汎化性能が悪かった、つまり、各クラスの特徴を一般化できていなかったと考えています。そこで次は、試料の数を増やし、クラスごとに30サンプルを用意しました。グリーンカルダモンが50粒、ブラックカルダモンが50粒あります。また、それにより撮影時間が大幅に増えそうなので、撮影角度を大幅に大きくして120度としました。合計で600枚の画像のうち、500枚を教師データとします。学習の結果は以下です。
# python transfer_learning.py cardamon2
Epoch 0/9
----------
train Loss: 0.6062 Acc: 0.6595
val Loss: 0.3957 Acc: 0.8441
...
...
...
Epoch 9/9
----------
train Loss: 0.2917 Acc: 0.8689
val Loss: 0.1027 Acc: 0.9839
Training complete in 1m 16s
Best val Acc: 0.989247
推論
テストとして推論に使用するスクリプトは以下です。
(cardamon.py)
まとめ
以上、試料の数を変えて、2回にわたり教師データの作成と学習を行いました。また、試料は多い方が、全体の教師データ数が小さいとしても、結果的な学習の質は良いことも分かりました。数の観点では、教師データが多すぎて性能が落ちるということはないのですが、しかし現実的には、時間やその他のリソースとのバランスを考える必要があり、十分な性能が得ら得る最小のサイズの教師データ数がポイントとなります。しかし、それは定量的に判断しにくく、感覚や経験が効いてくるところでもあります。ぜひこれを参考にしていただければ幸いです。
参考情報
[1]ディープラーニングにもセキュリティ問題、AIをだます手口に注意
https://tech.nikkeibp.co.jp/it/atcl/column/15/061500148/111400137/
[2]PyTorch
https://pytorch.org/
[3]ResNet
https://arxiv.org/abs/1512.03385
[4]TRANSFER LEARNING TUTORIAL
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html